
Authors:
(1) Luyang Zhu, University of Washington and Google Research, and work done while the author was an intern at Google;
(2) Dawei Yang, Google Research;
(3) Tyler Zhu, Google Research;
(4) Fitsum Reda, Google Research;
(5) William Chan, Google Research;
(6) Chitwan Saharia, Google Research;
(7) Mohammad Norouzi, Google Research;
(8) Ira Kemelmacher-Shlizerman, University of Washington and Google Research.
Table of Links
3.1. Cascaded Diffusion Models for Try-On
5. Summary and Future Work and References
Appendix
4. Experiments
Datasets. We collect a paired training dataset of 4 Million samples. Each sample consists of two images of the same
person wearing the same garment in two different poses. For test, we collect 6K unpaired samples that are never seen during training. Each test sample includes two images of different people wearing different garments under different poses. Both training and test images are cropped and resized to 1024×1024 based on detected 2D human poses. Our dataset includes both men and women captured in different poses, with different body shapes, skin tones, and wearing a wide variety of garments with diverse texture patterns. In addition, we also provide results on the VITONHD dataset [6].

Comparison with other methods. We compare our approach to three methods: TryOnGAN [26], SDAFN [2] and HR-VITON [25]. For fair comparison, we re-train all three methods on our 4 Million samples until convergence. Without re-training, the results of these methods are worse. Released checkpoints of SDAFN and HR-VITON also require layflat garment as input, which is not applicable to our setting. The resolutions of the related methods vary, and we present each method’s results in their native resolution: SDAFN’s at 256×256, TryOnGAN’s at 512×512 and HR-VITON at 1024 × 1024.
Quantitative comparison. Table 1 provides comparisons with two metrics. Since our test dataset is unpaired, we
![Figure 3. Comparison with TryOnGAN [26], SDAFN [2] and HR-VITON [25]. First column shows the input (person, garment) pairs. TryOnDiffusion warps well garment details including text and geometric patterns even under extreme body pose and shape changes.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-v6a30a5.png)
compute Frechet Inception Distance (FID) [16] and Kernel Inception Distance (KID) [3] as evaluation metrics. We computed those metrics on both test datasets (our 6K, and VITON-HD) and observe a significantly better performance with our method.
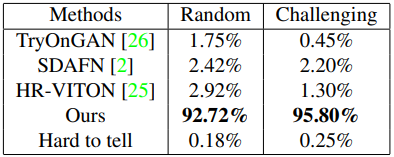
User study. We ran two user studies to objectively evaluate our methods compared to others at scale. The results are reported in Table 2. In first study (named “random”), we randomly selected 2804 input pairs out of the 6K test set, ran all four methods on those pairs, and presented to raters. 15 non-expert raters (on crowdsource platform) have been asked to select the best result out of four or choose “hard to tell” option. Our method was selected as best for 92.72% of the inputs. In a second study (named “challenging”), we performed the same setup but chose 2K input pairs (out of 6K) with more challenging poses. The raters selected our method as best for 95.8% of the inputs.
Qualitative comparison. In Figures 3 and 4, we provide visual comparisons to all baselines on two test datasets (our 6K, and VITON-HD). Note that many of the chosen input pairs have quite different body poses, shapes and complex garment materials–all limitations of most previous methods–thus we don’t expect them to perform well but present here to show the strength of our method. Specifically, we observe that TryOnGAN struggles to retain the texture pattern of the garments while SDAFN and HRVITON introduce warping artifacts in the try-on results. In contrast, our approach preserves fine details of the source garment and seamlessly blends the garment with the person even if the poses are hard or materials are complex (Fig. 3, row 4). Note also how TryOnDiffusion generates realistic garment wrinkles corresponding to the new body poses (Fig. 3, row 1). We show easier poses in the supplementary (in addition to more results) to provide a fair comparison to other methods.
![Figure 4. Comparison with state-of-the-art methods on VITON-HD dataset [6]. All methods were trained on the same 4M dataset and tested on VITON-HD.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-f2b30jb.png)
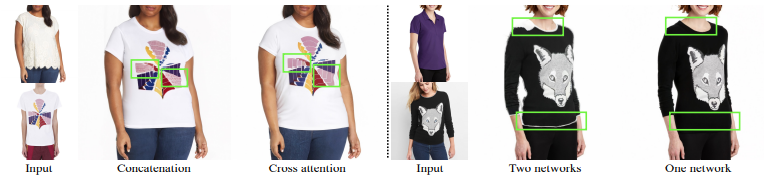
Ablation 1: Cross attention vs concatenation for implicit warping. The implementation of cross attention is detailed in Sec. 3.2. For concatenation, we discard the garmentUNet, directly concatenate the segmented garment Ic to the noisy image zt, and drop cross attention modules in the person-UNet. We apply these changes to each ParallelUNet, and keep the final SR diffusion model same. Fig. 5 shows that cross attention is better at preserving garment details under significant body pose and shape changes.



Limitations. First, our method exhibits garment leaking artifacts in case of errors in segmentation maps and pose estimations during preprocessing. Fortunately, those [11, 28] became quite accurate in recent years and this does not happen often. Second, representing identity via clothingagnostic RGB is not ideal, since sometimes it may preserve only part of the identity, e.g., tatooes won’t be visible in this representation, or specific muscle structure. Third, our train and test datasets have mostly clean uniform background so it is unknown how the method performs with more complex backgrounds. Finally, this work focused on upper body clothing and we have not experimented with full body tryon, which is left for future work. Fig. 6 demonstrates failure cases.
Finally, Fig. 7 shows TryOnDiffusion results on variety of people and garments. Please refer to supplementary material for more results.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.