Authors:
(1) Luyang Zhu, University of Washington and Google Research, and work done while the author was an intern at Google;
(2) Dawei Yang, Google Research;
(3) Tyler Zhu, Google Research;
(4) Fitsum Reda, Google Research;
(5) William Chan, Google Research;
(6) Chitwan Saharia, Google Research;
(7) Mohammad Norouzi, Google Research;
(8) Ira Kemelmacher-Shlizerman, University of Washington and Google Research.
Table of Links
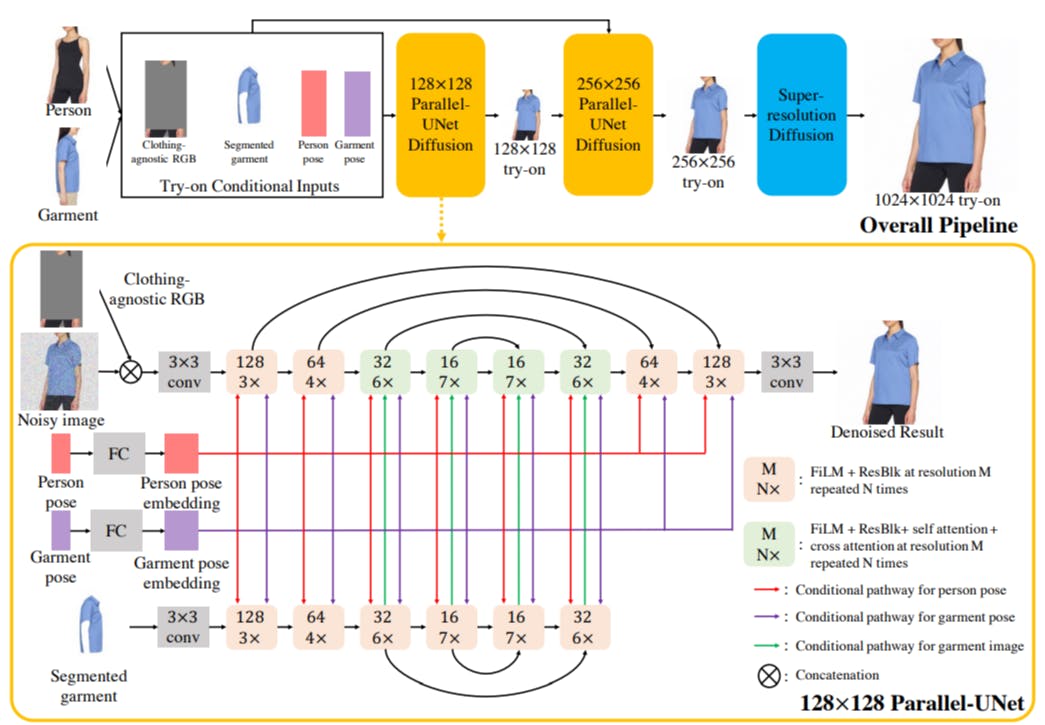
3.1. Cascaded Diffusion Models for Try-On
5. Summary and Future Work and References
Appendix
2. Related Work
Image-Based Virtual Try-On. Given a pair of images (target person, source garment), image-based virtual try-on methods generate the look of the target person wearing the source garment. Most of these methods [2, 6, 7, 10, 14, 15, 20,25,27,32,43,46–49] decompose the try-on task into two stages: a warping model and a blending model. The seminal work VITON [14] proposes a coarse-to-fine pipeline guided by the thin-plate-spline (TPS) warping of source garments. ClothFlow [13] directly estimates flow fields with a neural network instead of TPS for better garment warping. VITON-HD [6] introduces alignment-aware generator to increase the try-on resolution from 256×192 to 1024×768. HR-VITON [25] further improves VITON-HD by predicting segmentation and flow simultaneously. SDAFN [2] predicts multiple flow fields for both the garment and the person, and combines warped features through deformable attention [50] to improve quality.
Despite great progress, these methods still suffer from misalignment brought by explicit flow estimation and warping. TryOnGAN [26] tackles this issue by training a poseconditioned StyleGAN2 [23] on unpaired fashion images and running optimization in the latent space to achieve tryon. By optimizing the latent space, however, it loses garment details that are less represented by the latent space. This becomes evident when garments have a pattern or details like pockets, or special sleeves.
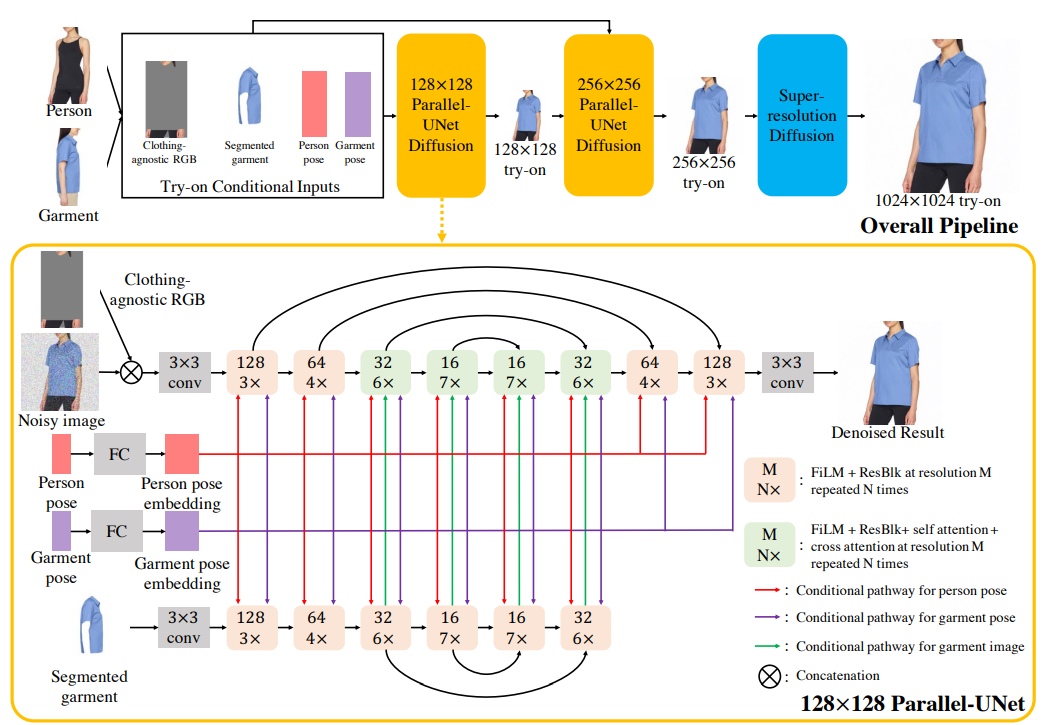
We propose a novel architecture which performs implicit warping (without computing flow) and blending in a single network pass. Experiments show that our method can preserve details of the garment even under heavy occlusions and various body poses and shapes.
Diffusion Models. Diffusion models [17, 39, 41] have recently emerged as the most powerful family of generative models. Unlike GANs [5, 12], diffusion models have better training stability and mode coverage. They have achieved state-of-the-art results on various image generation tasks, such as super-resolution [38], colorization [36], novel-view synthesis [44] and text-to-image generation [30, 33, 35, 37]. Although being successful, state-of-the-art diffusion models utilize a traditional UNet architecture [17, 34] with channel-wise concatenation [36,38] for image conditioning. The channel-wise concatenation works well for image-toimage translation problems where input and output pixels are perfectly aligned (e.g., super-resolution, inpainting and colorization). However, it is not directly applicable to our task as try-on involves highly non-linear transformations like garment warping. To solve this challenge, we propose Parallel-UNet architecture tailored to try-on, where the garment is warped implicitly via cross attentions.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.